Русский
Русский  English (UK)
English (UK) Приложение Issuecrawler обрабатывает веб-страницы и "вытаскивает" из них ссылки на другие страницы в сети Интернет. Данное приложение может быть использовано, если вам необходимо построить сеть организации в сети Интернет, т. е. увидеть, каким образом "связаны" некоторые веб-страницы. Вы также можете проанализировать сети веб-страниц организаций одной тематики, будь то сайты международных некоммерческих организаций по защите лиц, страдающих альбинизмом, либо сайты органов, связанных с борьбой с коррупцией, либо сайты информационных агентств. Технически вы можете обработать в Issuecralwer любые веб-страницы, однако, не все веб-страницы и их ссылки построят сеть. С другой стороны, тот факт, что веб-страницы не выстраивают сеть, тоже является результатом исследования. Разберем на примере, каким образом выстроить сеть между веб-страницами при помощи Issuecrawler.
В нашем примере мы разберем работу Issuecrawler на примере веб-страниц факультетов одного куста Санкт-Петербургского государственного университета:
http://politology.spbu.ru
http://sir.spbu.ru
http://soc.spbu.ru
http://www.econ.spbu.ru
Приложение Issuecrawler покажет нам сеть данных веб-страниц с другими страницами в сети Интернет. Связью в этой сети будет ссылка на другую веб-страницу, узлом будет являться веб-страница.
1. Для начала перейдите по адресу https://www.issuecrawler.net/ и запросите аккаунт "Request account". После заполнения краткой формы Вам вышлют на электронную почту пароль, однако, одобрение аккаунта вы получите несколько позднее. Сохраните логин и пароль.
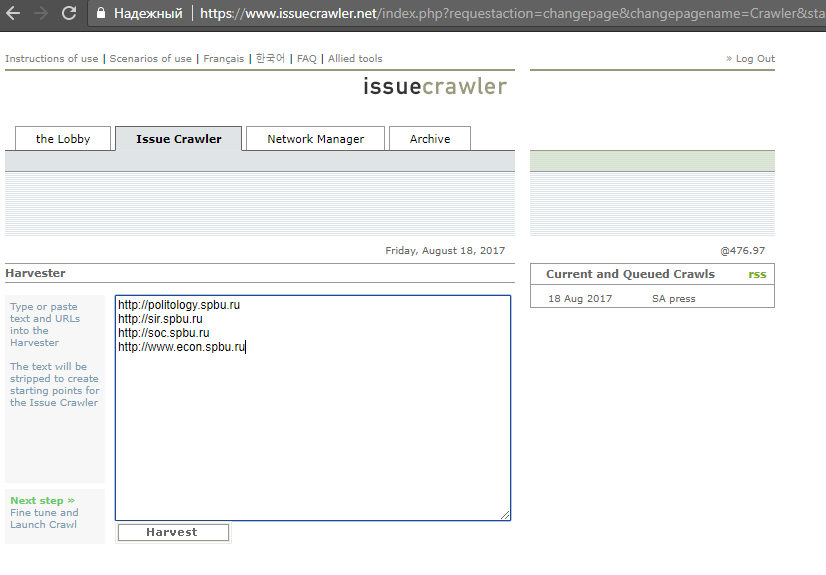
2. После одобрения аккаунта зайдите в Issuecrawler по адресу https://www.issuecrawler.net/ . Зайдите в ваш аккаунт. Вы видите четыре поля: the Lobby, Issue Crawler, Network Manager, Archive. Начинать работу необходимо с поля Issue Crawler. В этом поле введите веб-адреса факультетов, как на картинке ниже. Уже после обработки данных, в поле Network Manager вы найдете результаты.
3. После ввода веб-страниц нажмите Harvest. Вы увидите три метода обработки веб-страниц (Crawling methods): Co-link, Snowball, Inter-actor, - и настройки к каждому из методов (Settings). Вы можете использовать любой из трех методов. Остановимся на них подробнее.
Метод 1 "Co-link"
При выборе данного метода приложение "вытаскивает" из указанных страниц (а также подстраниц - страниц указанных хостов) ссылки на иные сайты в сети Интернет и проверяет, какие ссылки есть, как минимум, у двух из указанных страниц. Если ссылки есть, как минимум, у двух из указанных страниц, то ссылки попадают в сеть в качестве узлов сети. Далее приложение проверяет, ссылаются ли "вытащенные" ссылки друг на друга.*
Метод 2 "Snowball"
При выборе данного метода приложение "вытаскивает" ссылки из указанных страниц, а также ссылки из "вытащенных" ссылок. Отличие от первого метода: все вытащенные ссылки попадают сеть, в том числе если ссылка "вытащена" из ОДНОЙ из указанных страниц. Данный метод подойдет, если при первом сеть не обнаружена либо если у вас стоит задача посмотреть, например, информационное поле вокруг двух веб-страниц.
Метод 3 "Inter-actor"
Третий метод похож на первый, однако, его отличие в том, что он включает в сеть только ссылки с указанных хостов, а также включает в сеть заданные страницы.
*Примечание: количество анализируемых ссылок ограничено и может быть исправлено в разделе Setting - Ceilings (advanced). Так, по умолчанию максимальное количество "вытаскиваемых" ссылок из одного хоста составляет 500, а максимальное количество ссылок за одно обращение (iteration) составляет 40000.
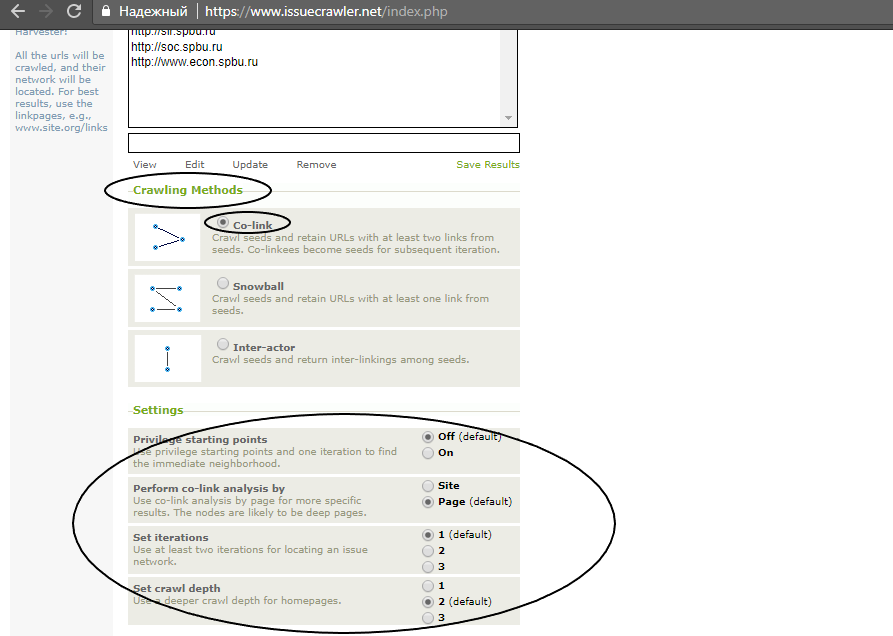
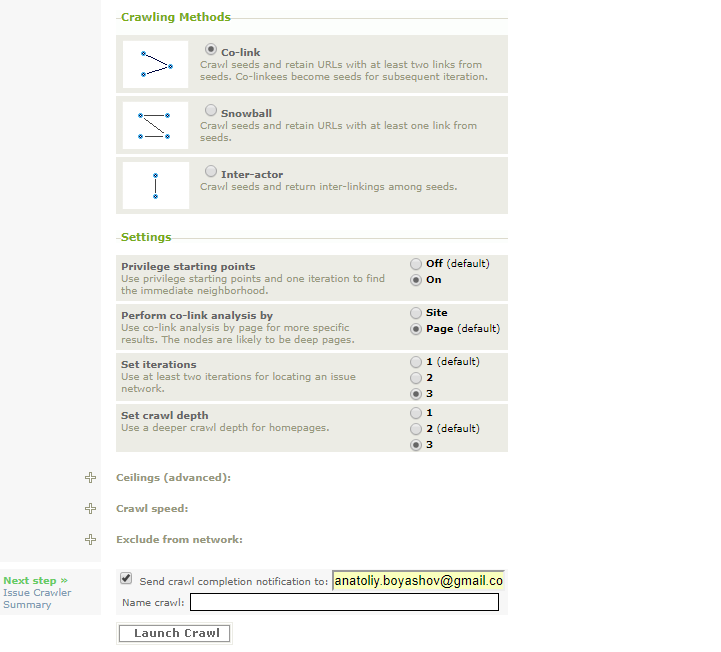
4. Итак, в нашем примере мы воспользуемся методом 1 Co-link. Настройки следующие: Privilege starting points - On (для того, чтобы сохранить исходные веб-страницы в сети), Perform co-link analysis by - Page (для того, чтобы вытаскивать ссылки по страницам, а не по хостам. Нас интересует распространение информации среди университетских сайтов и подстраниц, по этой причине, выбирая Page, мы получим больше информации), Set iterations - 3 (с целью обработать больше ссылок, в этом случае максимальное количество ссылок 120000 и 1500 ссылок с одного хоста), Set crawl depth - 3 (для того, чтобы обработать данные подстраниц указанных веб-страниц. Выбирайте 2 или 3, если вы задаете домашнюю страницу, как в нашем примере).
На подобный запрос уйдет около шести часов, поэтому не забудьте поставить галочку и указать адрес электронной почты. По нему вам пришлют уведомление о завершении сбора данных. Задайте имя для проекта (Name crawl). Нажмите Launch.
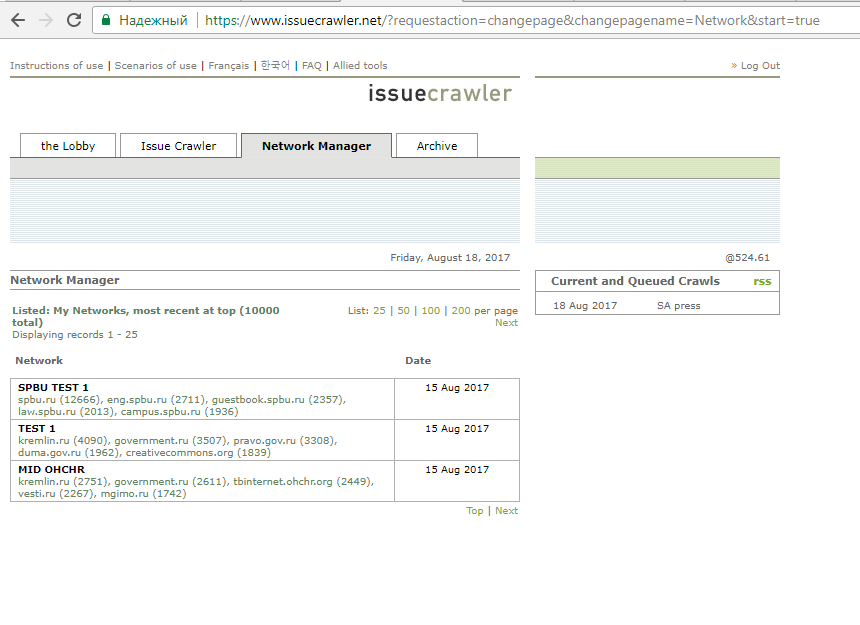
5. Далее дождитесь уведомления о выполнении сбора данных. Зайдите на https://www.issuecrawler.net/ и перейдите на вкладку Network manager. Вы увидите выполненный проект, нажмите на него. В нашем примере это SPBU TEST 1.
6. После клика на проект вы увидите страницу, где можно визуализировать сеть (Select Network Depiction - Cluster), а также ссылки внизу на сами данные. Также можно скачать файл для последующей визуализации в Gephi, Netminer или Ucinet. Вам предложены:
- xml source file - файл с данными в формате xml;
- raw data (comma separated) - сырые данные в формате txt, отделены запятой, хорошо подойдут для последующего анализа в Tableau;
- retrieve startingpoints and network urls - изначальных веб-страниц и проанализированных ссылок;
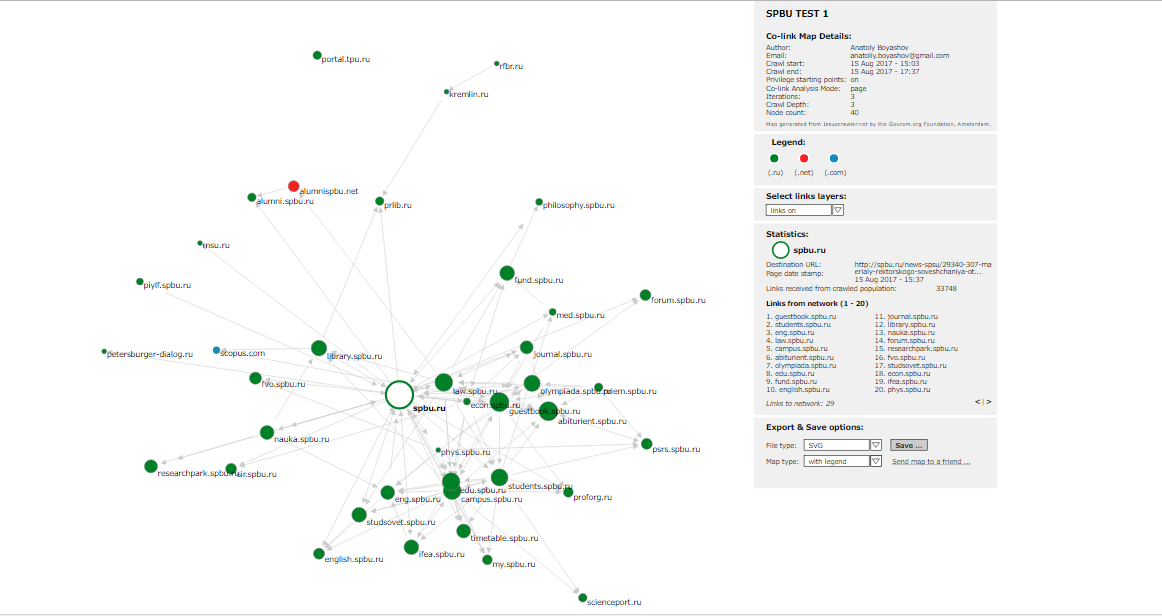
- ranked actor list by inlink count from total network (by page) - ранжированный список узлов в соответствии с количеством входящих ссылок со страниц (TOP5 в нашем примере: spbu.ru, guestbook.spbu.ru, law.spbu.ru, campus.spbu.ru, eng.spbu.ru;
- ranked actor list by inlink count from total network (by site) - ранжированный список узлов в соответствии с количеством входящих ссылок с сайтов (TOP5 в нашем примере: spbu.ru, guestbook.spbu.ru, campus.spbu.ru, abiturient.spbu.ru, eng.spbu.ru. Мы видим, что из второго списка TOP5 исчез сайт юридического факультета, но появился сайт для абитуриентов. Это произошло, так как на последний из того, что вошло в нашу сеть, ссылается больше внешних сайтов);
- ranked actor list by inlink count from crawled population - ранжированный список узлов в соответствии со всеми обработанными ссылками, в т. ч. и не вошедшими в сеть;
- ranked list of pages per node - ранжированный список страниц в соответствии с количеством ссылок из центра и периферии сети. В нашем примере на третье место по совокупности ссылок из периферии выходит веб-страница Центра экспертиз;
- actor list with interlinkings/non-matrix version - матрица перекрестных ссылок узлов сети, в нашем примере видно, что большинство перекрестных ссылок сосредоточены на сайте spbu.ru;
- page list with their interlinkings - список страниц со списком ссылающихся на них страниц. Так, в списке мы видим, например, откуда идут ссылки на Центр экспертиз, а откуда нет, где больше публикуется информации о Научном парке, а где меньше и т. д.;
- Export core network to GEXF (open with Gephi, instructions) - экспорт файла для работы в Gephi;
- UCInet / NetMiner compatible data file - экспорт файла для работы в UCInet или Netminer.
Для визуализации сети нажмите Cluster - View depiction. После того, как появится сети, обратите внимание на легенду. Там есть настраиваемые поля. Если вы выберете Links Off, вы сможете кликать на узлы сети и выводить на легенду информацию о каждом узле в отдельности. Размер узла зависит от количества входящих ссылок. Связь - ссылка на веб-страницу. В сеть попали только те сайты, на которые ссылались как минимум две страницы из заданных в самом начале четырех. С учетом летнего времени - сбор данных произведен 14-15 августа 2017 г. - очевидно, в топ выбиваются страницы, посвященные приему абитуриентов. Видно, что, в целом, распространение информации носит централизованный характер. В то же время, среди попавших в сеть факультетов выбиваются философский и международных отношений, они выпадают из центра сети. Видно, что выпадает из центра сети и сайт Ассоциации выпускников: по-видимому, в плане наполнения сайтов Ассоциация работает больше с главным зданием и юридическим факультетом. Необходимо помнить, что в сеть попали только те веб-страницы, на которые ссылаются, как минимум, две из четырех заданных. Другими словами, это сеть тех страниц, которые наиболее проработаны в информационном плане на сайтах четырех факультетов куста. Более детальные выводы можно сделать из подробного анализа сайтов четырех факультетов по парам. Справа в нижней части легенды можно сохранить визулизацию в различных форматах.